Marco Rendina: Let's start by unpacking OCR. What is it, and why is it relevant to the preservation of cultural heritage?
Tom Vanallemeersch: OCR (Optical Character Recognition) or HTR (Handwritten Text Recognition) is a technology that produces a digital transcript of printed or handwritten texts. Transcriptions of scanned documents are mainly important for searchability as they allow keywords to be used to look for a specific document or to search for a specific part within a document. To further enhance this searchability, transcriptions can be translated using machine translation, enabling users to search for words in documents in different languages using, for example, only an English search term.
MR: How effective is current state-of-the-art OCR technology?
TV: Recent years have seen remarkable progress in OCR technology, and some OCR models perform impressively well, especially on modern printed texts. There is also a wide array of increasingly specialised models catering for different needs, such as 18th-century texts or handwritten WWII letters.
However, despite these advancements, challenges persist due to factors like different handwriting styles and text layouts, the languages involved, or the presence of ‘noise’ (degraded characters or bleed-through in double-paged documents, where the ink of the backside appears on the front side). Issues like the misrecognition of characters can dramatically impact the accuracy of OCR transcriptions, a problem that becomes particularly evident when these outputs are used for translation purposes.
Based on our experience at CrossLang with the development of systems for multilingual document processing and translation automation, we addressed these challenges head-on to ensure that the OCR output is not just accurate, but also translation-ready.
MR: Can you walk us through how you make OCR transcriptions ready for translation?
TV: Certainly. Making the transcriptions translation-ready is a multi-step process.
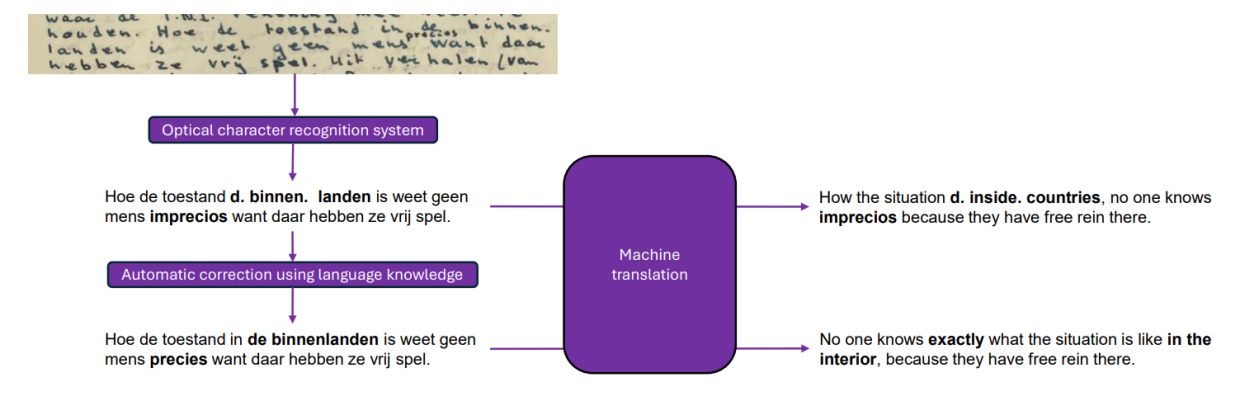
Firstly, the document or image is uploaded, and OCR technology is applied to generate a digital transcript. This involves analysing the page layout and identifying characters in the text areas. This process being automated, the resulting output may contain errors such as character misrecognition and missing spaces. Additionally, the OCR output typically lacks segmentation, presenting lines of printed or handwritten characters as they are displayed in the image, without any segmentation into sentences. While this might be fine as long as the end-user can read the text in the original language, using the OCR output directly, including its spelling errors and lack of segmentation, will very likely result in inaccurate translations.
We employ various techniques to address these inaccuracies. I’ll mention two main approaches. First, segmentation and dehyphenation techniques are employed to identify and separate sentences within the text and remove word-splitting hyphens at the end of lines. Second, to further enhance the accuracy of the OCR output, we use lexicon-based tools and Large Language Models (LLMs), including open-source chatbots, for automatically identifying and correcting errors in words to align the text as closely as possible with the original image.
Finally, with the corrected OCR output, MT can be applied to generate translations that are more accurate. This step relies on the quality of the input text, making the previous two automatic correction steps crucial for achieving useful MT results.