Meet the Members Council: Vladimir Alexiev
In 1992, five friends and I founded Sirma AI; in 24 years it has grown to be the largest Bulgarian software group (Sirma Group) with 400 staff and 12 spin-offs. It had an IPO on the Bulgarian Stock Exchange last year. I’ve always worked for Sirma companies. Managing some large projects motivated me to get a PMP certification and since 2009, I've taught IT Project Management at the New Bulgarian University.
“AI” in the original company name stood for Artificial Intelligence, and we’ve always sought to take interesting, challenging and research-oriented projects. The unit that best realised these dreams is Ontotext Corp, which started as a research lab in 2000, got VC investment and spun off as an independent company in 2008. I joined Ontotext in 2010, working on data, conversions, metadata, ontologies. You can find out more about this in my publications/presentations.
Introducing Ontotext
Ontotext works on Semantic Technologies: semantic data integration, deduplication and coreferencing, ontology engineering, RDF repository (database), semantic text analysis and enrichment, conceptual and faceted search... This sounds abstract and complex, but it’s all about extracting knowledge from text and disparate data sources, and interlinking it. A big part of it is using and developing the LOD cloud to allow more and better links.
In all kinds of domains (from life sciences to product lifecycle management, biodiversity to e-Government, publishing to Holocaust studies), professional communities face similar problems: large numbers of disparate data sources and texts that vary in language, terminology, database/metadata schemas, and so on. This disjointedness raises barriers to effective research and collaboration, and semantic technologies promise to lower these barriers.
Ontotext invests heavily in research and has worked on 36 EU research projects since 2001.
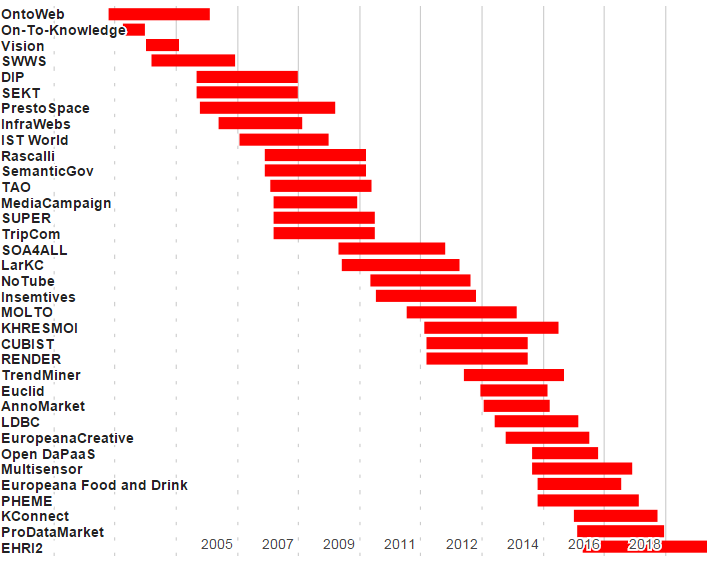
(Interactive version with links to project information)
Since 2008 Ontotext has had a strong focus on commercial projects, and struck gold in 2012 with the first massive industrial application of semantic technologies - the BBC Sports linked data platform. A whole new genre of Dynamic Semantic Publishing appeared, and many others followed this lead. Publishing (media, scientific, technical, financial) is now our strongest business, with clients such as BBC, UK & NL Press Associations, Financial Times, Euromoney, Oxford University Press, Wiley, IET and so on.
So what’s the relation between Semantic Technologies and Cultural Heritage?
Semantic technologies are appropriate to cultural heritage (CH) for these reasons:
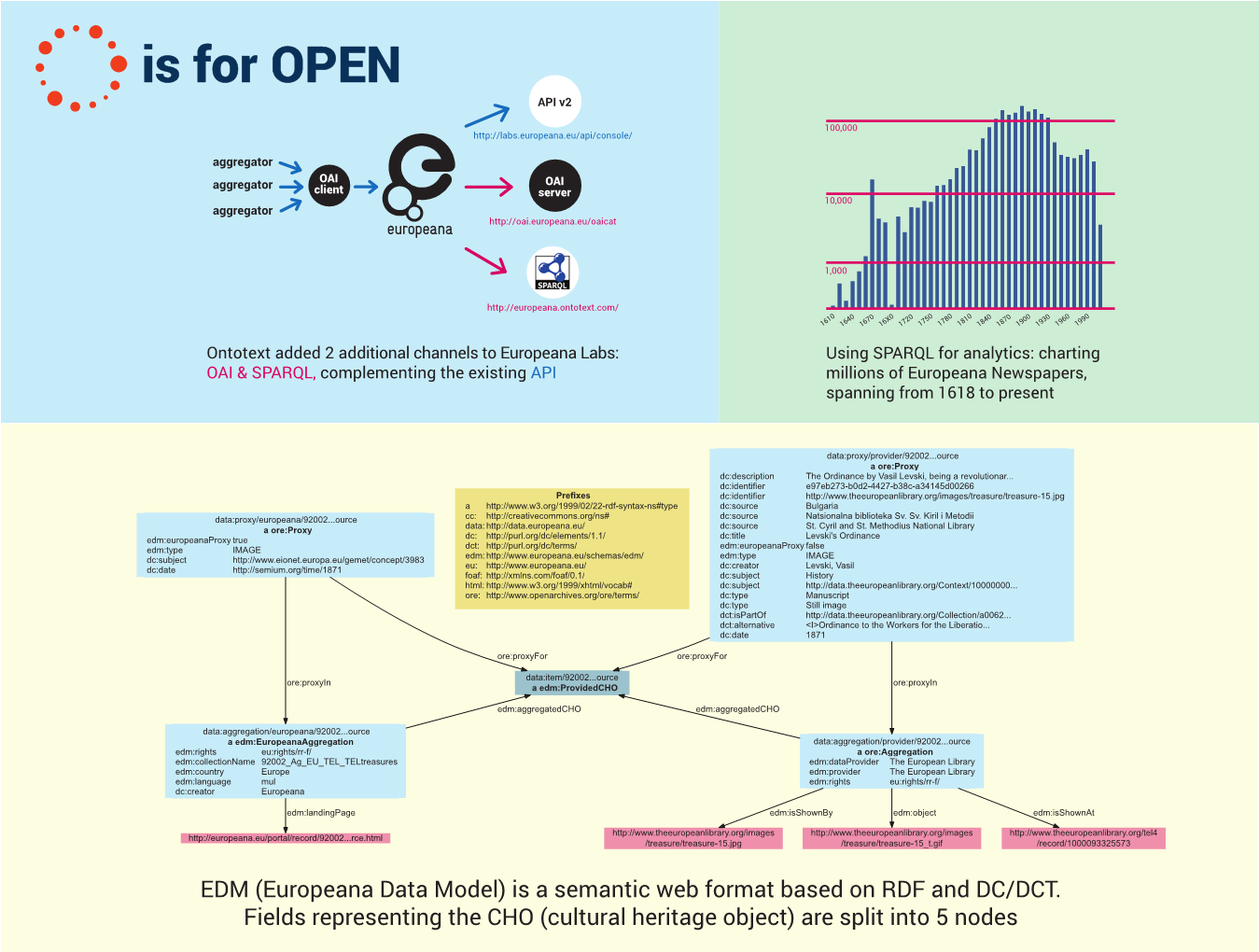
- CH data is complex and spread over disparate systems: its semantic integration better enables use and research. The Europeana Data Model is based on RDF.
- Culture is by its very nature international and multilingual, so the value of interlinking CH data is immense.
- Semantic enrichment will play a big role to make CH objects better searchable and interlinked.
My work in CH began in 2010. Ontotext initiated Bulgariana, an Europeana aggregator and NGO promoting CH in Bulgaria. We are active in establishing CLARIN and DARIAH in Bulgaria.
We developed the ResearchSpace prototype for the British Museum, gaining strong experience with the CIDOC CRM and FRBRoo ontologies. I helped mapping Yale Center for British Art data to CRM, and I’m currently mapping one of the most important museum & architecture aggregations to CRM.
We also published as LOD some of the most important thesauri in the CH domain and contributed to the development of the ISO 25964 ontology (latest standard on thesauri).
Collaborating with Europeana
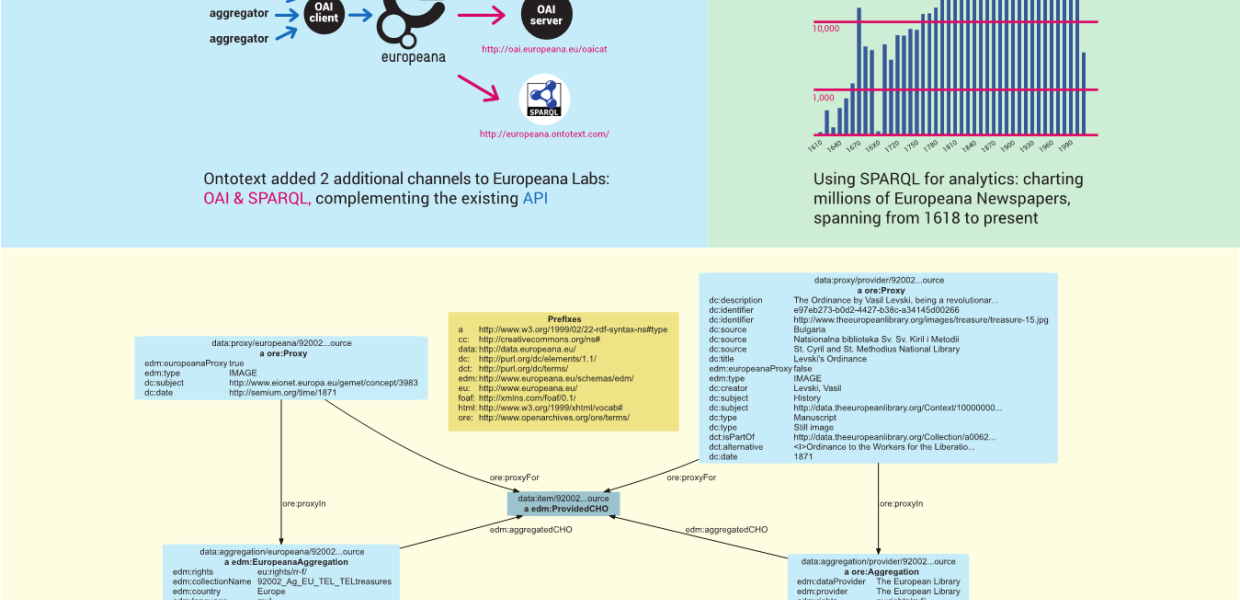
In Europeana Creative we worked on semantic enrichment: geo-referencing, crowdsourcing, researched Name Data Sources for Semantic Enrichment. We added two new access channels in Europeana Labs: OAI and SPARQL; see Ontotext contributes to 3 KPIs of Europeana.
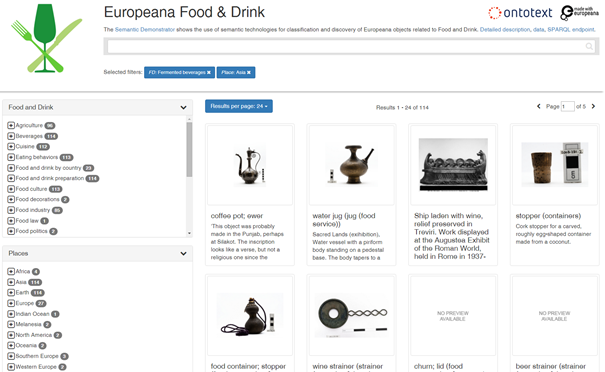
In Europeana Food and Drink we developed a Food and Drink classification based on Wikipedia categories, semantic enrichment of English & Bulgarian collections (now working on French), and a semantic demonstrator. It is like a “mini-Europeana” but in addition to flat facets (provider, dataProvider, country, type) we created semantic facets for Places and FD Topics. This enables semantic hierarchical browsing and “precision search”, e.g. Objects Related to Fermented Beverages and Asia.
Last but not least, I have also participated in five Europeana Task Forces, mostly on technical topics:
- EDM and FRBRoo Application Profile
- Multilingual Enrichment Strategy
- Evaluation and Enrichments
- Europeana for Education
- Free, Libre, Open Source Software
Quality is priority #1 in the Europeana Strategy 2015-2020. This change in emphasis from Quantity to Quality is important for Europeana's consumers, and I am excited to be on the DBpedia and Europeana quality committees. We can take a multi-pronged approach to data quality:
- Work with the Europeana Aggregator forum to adopt quality standards and best practices
- Deploy data problem discovery and reporting tools and creating a feedback loop back to the data providers
- Work on semantic enrichment to expose meaning currently hidden in text fields
- Deepen EDM deployment to accommodate more elaborate data - for instance, we can use edm:Event to express the particular role a Contributor had in object creation
I look forward to representing you in all this work - let me know if you have any questions. #AllezCulture.